有没有听说过“ 布兰妮斯皮尔斯问题 ”?与它听起来相反,它与富人和名人的dalliances无关。相反,它是与数据跟踪相关的计算难题:为个人用户精确定制数据丰富的服务(如搜索引擎或光纤互联网连接),假设需要跟踪发送到服务提供商和从服务提供商发送的每个数据包,这不用说是不是实用。为了解决这个问题,大多数公司利用算法来猜测通过散列数据来交换数据的频率(即将其分解成碎片)。但这必然会牺牲细微差别 - 在大数据量中自然出现的模式在雷达下飞行。
幸运的是,麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员相信他们已经设计出一种依赖于机器学习的可行替代方案。在一篇新发表的论文(“ 基于学习的频率估计算法 ”)中,他们描述了一个系统 - 被称为LearnedSketch,因为它“勾勒”数据流中的数据 - 预测特定数据元素是否会比其他数据更频繁地出现并且,如果它们实际上是这样做的,则将它们与其余的散列部分自动地分开。
该论文的作者称,这是第一种基于机器学习的方法,不仅用于频率估计,而且用于流式算法,这是一类算法,其中输入数据作为序列呈现,并且只能在几次通过中检查。在许多应用程序中,它们广泛用于安全系统和自然语言处理管道。
“[S] treaming算法通常假定通用数据,并且不利用其输入的有用模式或属性,”该团队解释说。“例如,在文本数据中,已知单词频率与单词的长度成反比。类似地,在网络数据中,某些应用程序往往比其他应用程序产生更多的流量。如果可以利用这些属性,可以设计出比现有算法更有效的频率估算算法。“
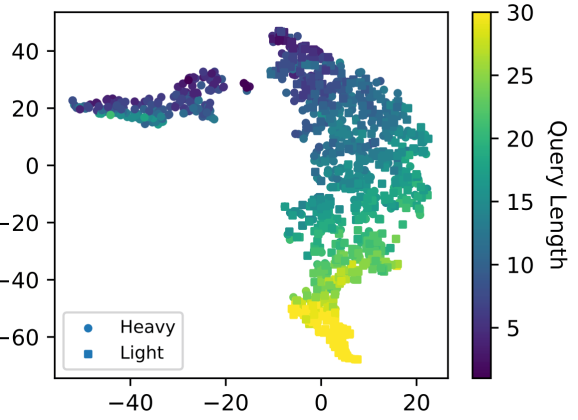
在实验中,LearnedSketch展示了检测和隔离丰富数据的能力。例如,对来自第1层ISP的2.1亿个数据包进行了培训,它的性能优于现有的估算网络中互联网流量的方法,误差减少了57%。并且考虑到380万个独特的AOL查询,它设法估算了互联网搜索字词的查询数量,误差减少了71%。
而且,LearnedSketch非常普遍; 它学到的结构可以应用于以前从未见过的物品。在一项实验中,它负责确定哪些互联网连接具有最多流量,它通过其目标IP地址的前缀对不同连接进行聚类,表明对生成大流量的互联网订户倾向于共享特定前缀的规则的认识。
研究人员认为,LearnedSketch(或类似人工智能系统)有朝一日可用于跟踪社交媒体上的热门话题,或识别网络流量中的麻烦高峰并改善电子商务网站的产品推荐。但实际上,博士生和合着者陈宇宇说,天空是极限。
“这些结果表明,机器学习是一种可以与经典算法范例一起使用的方法,如”分而治之“和动态编程,”Hsu补充道。“我们将模型与经典算法结合起来,以便我们的算法自然地从经典算法中继承最坏情况的保证。”